Rear view of Wilbur Wright making a right turn with the Wright Glider, 1902. (source: Wikimedia Commons)
Planning a Database
So far in this book, we have only learned how to be consumers of data with the SELECT statement. We have done analysis operations that read data and transform it in interesting ways, but none of this physically changes the data in the tables. A SELECT statement is a read-only operation. Sometimes, though, we will want to CREATE new tables, as well as INSERT, UPDATE, and DELETE records.
When you create your own tables to support your business, it should not be done lightly. You need to plan carefully because bad database design is sure to cause regrets down the road. There are critical questions that should drive your design:
Learn faster. Dig deeper. See farther.
Join the O'Reilly online learning platform. Get a free trial today and find answers on the fly, or master something new and useful.
What tables will I need to fulfill those requirements?
What columns will each table contain?
How will the tables be normalized?
What will their parent/child relationships be?
It might be a good idea to draft a diagram showing the tables and how they are related. But design is not the only factor to consider. Populating data should be part of the planning process too. If the data is not maintainable and kept up to date, then the design has already failed. This factor is often overlooked and can easily cause a database project to fail.
Data questions
How much data will be populated into these tables?
Who/what will populate the data into these tables?
Where will the data come from?
Do we need processes to automatically populate the tables?
Data inception has to happen somewhere. Depending on the nature of the data, it can be created within your organization or received from an external party. If you need to store a high volume of data that updates regularly, chances are a human cannot do this task manually. You will need a process written in Java, Python, or another coding language to do that.
Although security and administration are beyond the scope of this book, centralized databases usually are concerned with these areas. Administrating privileges and security is a full-time job in itself and often done by database administrators (DBAs). For centralized databases, security factors should be considered.
Security questions
Who should have access to this database?
Who should have access to which tables? Read-only access? Write access?
Is this database critical to business operations?
What backup plans do we have in the event of disaster/failure?
Should changes to tables be logged?
If the database is used for websites or web applications, is it secure?
Security is often a tough topic to address. Excessive security creates bureaucracy and obstructs nimbleness, but insufficient security will invite calamity. Like with any complex issue, a balance between the two extremes has to be found. But security should become a high priority when the database is used for a website. Connecting anything to the Web makes it more vulnerable to leaks and malicious attacks.
Note
One of the most common malicious hacks is SQL injection. If a web developer has failed to implement security measures in a website, you can type a carefully crafted SELECT statement right inside a web browser, and get the query results displayed right back to you! 130 million credit card numbers were stolen this way in 2009.
SQLite has few security or administrative features, as these features would be overkill in a lightweight database. If your SQLite databases need to be secured, protect the database files the same way you would any other file. Either hide them, copy them to a backup, or distribute copies to your coworkers so they do not have access to the “master copy.”
With all these considerations in mind, let’s design our first database.
The SurgeTech Conference
You are a staff member for the SurgeTech conference, a gathering of tech startup companies seeking publicity and investors. The organizer has tasked you with creating a database to manage the attendees, companies, presentations, rooms, and presentation attendance. How should this database be designed?
First, review the different entities and start thinking about how they will be structured into tables. This may seem like a large number of business asks to capture, but any complex problem can be broken down into simple components.
ATTENDEE
The attendees are registered guests (including some VIPs) who are checking out the tech startups. Each attendee’s ID, name, phone number, email, and VIP status will need to be tracked.
Taking all this information, we may design the ATTENDEE table with these columns:
Figure 1-1.
COMPANY
The startup companies need to be tracked as well. The company ID, company name, company description, and primary contact (who should be listed as an attendee) for each must be tracked:
Figure 1-2.
PRESENTATION
Some companies will schedule to do a presentation for a specific slot of time (with a start time and end time). The company leading the presentation as well as a room number must also be booked for each presentation slot:
Figure 1-3.
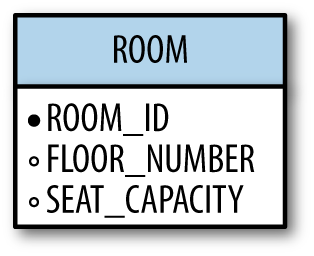
ROOM
There will be rooms available for the presentations, each with a room ID number, a floor number, and a seating capacity:
Figure 1-4.
PRESENTATION_ATTENDANCE
If attendees are interested in hearing a company’s presentation, they can acquire a ticket (with a ticket ID) and be allowed in. This will help keep track of who attended what presentations. To implement this, the PRESENTATION_ATTENDANCE table will track the ticket IDs and pair the presentations with the attendees through their respective IDs to show who was where:
Figure 1-5.
Primary and Foreign Keys
You should always strive to have a primary key on any table. A primary key is a special field (or combination of fields) that provides a unique identity to each record. A primary key often defines a relationship and is frequently joined on. The ATTENDEE table has an ATTENDEE_ID field as its primary key, COMPANY has COMPANY_ID, and so on. While you do not need to designate a field as a primary key to join on it, it allows the database software to execute queries much more efficiently. It also acts as a constraint to ensure data integrity. No duplicates are allowed on the primary key, which means you cannot have two ATTENDEE records both with an ATTENDEE_ID of 2. The database will forbid this from happening and throw an error.
Note
To focus our scope in this book, we will not compose a primary key off more than one field. But be aware that multiple fields can act as a primary key, and you can never have duplicate combinations of those fields. For example, if you specified your primary key on the fields REPORT_ID and APPROVER_ID, you can never have two records with the same combination of REPORT_ID and APPROVER_ID.
Do not confuse the primary key with a foreign key. The primary key exists in the parent table, but the foreign key exists in the child table. The foreign key in a child table points to the primary key in its parent table. For example, the ATTENDEE_ID in the ATTENDEE table is a primary key, but the ATTENDEE_ID in the PRESENTATION_ATTENDANCE table is a foreign key. The two are joined together for a one-to-many relationship. Unlike a primary key, a foreign key does not enforce uniqueness, as it is the “many” in a “one-to-many” relationship.
The primary key and foreign key do not have to share the same field name. The BOOKED_COMPANY_ID in the PRESENTATION table is a foreign key pointing to the COMPANY_ID in its parent table COMPANY. The field name can be different on the foreign key to make it more descriptive of its usage. In this case, BOOKED_COMPANY_ID is more descriptive than just COMPANY_ID. The semantics are subjective but still legitimate as long as the business wording is clear.
The Schema
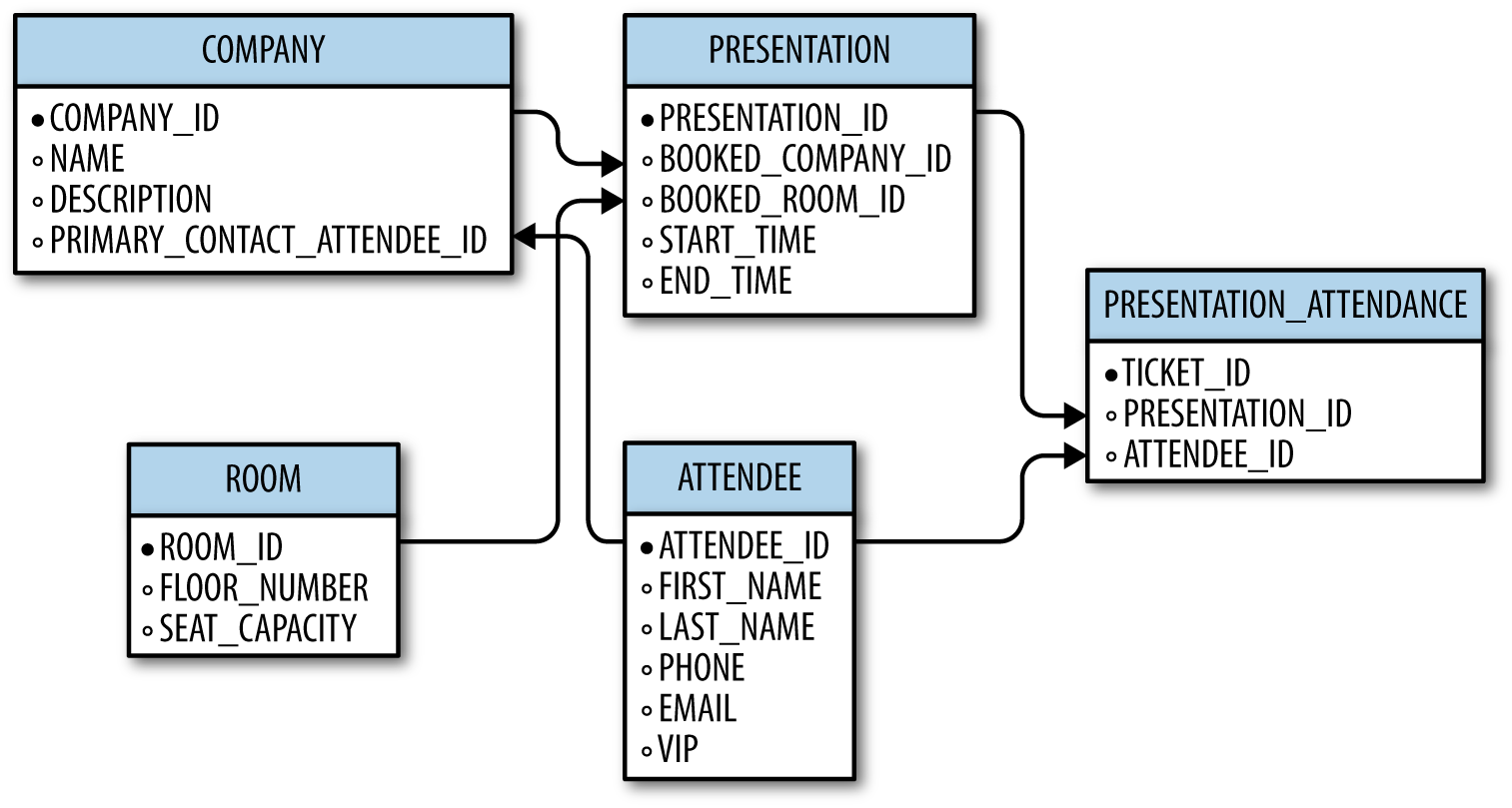
Applying our knowledge of primary keys and foreign keys, we can establish the relationships between these five tables and draw a database schema as shown in Figure 1-6. A database schema is a diagram showing tables, their columns, and their relationships. All the primary keys and foreign keys are connected by arrows. The non-tipped side of the arrow ties to a primary key, while the tipped side points to a foreign key. These arrows visualize how each parent table supplies data to a child table.
Figure 1-6. The database schema for the SurgeTech conference, with all tables and relationships
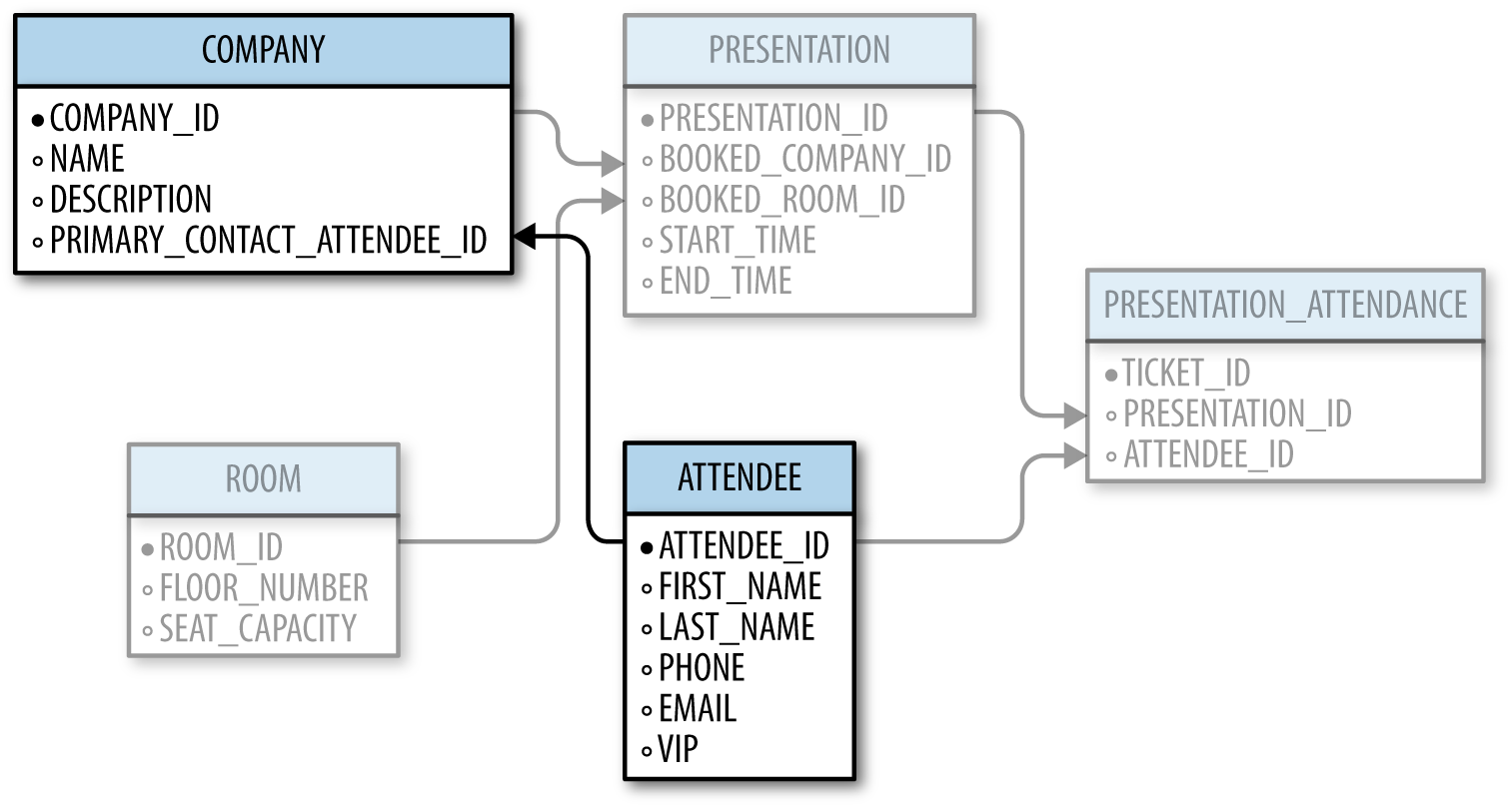
It can be overwhelming to look at these tables and relationships all at once. But all complex structures can be broken down into simple pieces. Chances are you will never write a SELECT query that uses all the tables, and you probably will only SELECT from two (maybe three) tables. Therefore, the secret to observing a schema is to focus only on two or three tables and their relationships at a time. While you analyze your drafted design, you can ensure the tables are efficiently normalized and primary/foreign keys are used effectively (Figure 1-7).
Figure 1-7. Focusing on just two tables and their relationships (here we can easily see the PRIMARY_CONTACT_ATTENDEE_ID supplies name and contact information from the ATTENDEE table)
If you can successfully visualize different SELECT queries and joins you would typically use on the data, the database schema is probably sound.
Creating a New Database
With a well-planned design, it is now time to actually create this database. We are going to use SQLiteStudio’s tools to create the tables and components. But along the way, SQLiteStudio will show us the SQL it uses to create and modify our tables.
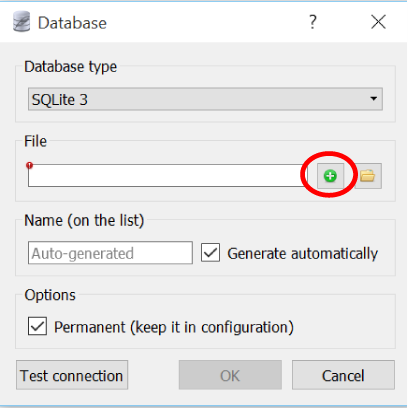
First, navigate to Database→Add a Database (Figure 1-8).
Figure 1-8. Adding a database
Click the green “plus” button circled in Figure 1-9 to create a new database.
Figure 1-9. Creating a database
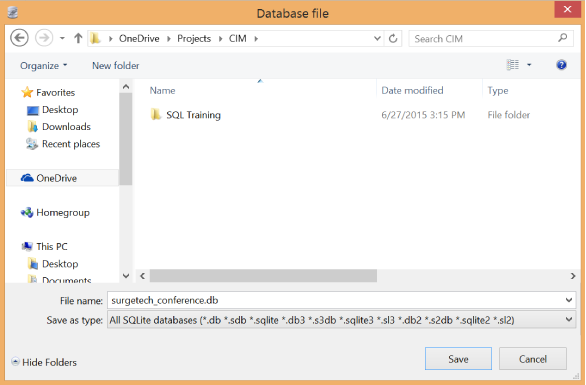
Browse to the folder you would like to save the database to. In the “File name” field, provide a name for the database file. It usually is good practice to end the name with the file extension .db. In this case, we might name it surgetech_conference.db (Figure 1-10).
Figure 1-10. Selecting a location to create a database
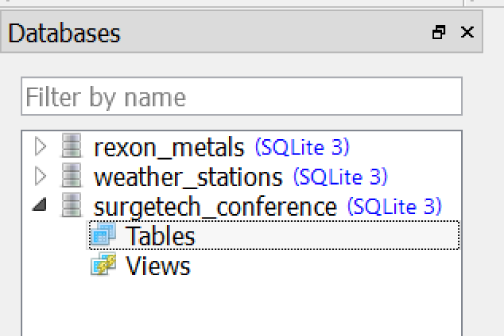
Click Save, then OK. You should now see the new database in your navigator (Figure 1-11).
Figure 1-11. Our new surgetech_conference database
This database is empty, so next we will add some tables to it.
CREATE TABLE
When we create a table in SQL, we use a CREATE TABLE statement. However, I am an advocate for using tools that make tasks easier. We are going to use SQLiteStudio’s visual tools to create the table, and when we are done it will generate and display the CREATE TABLE statement it built for us.
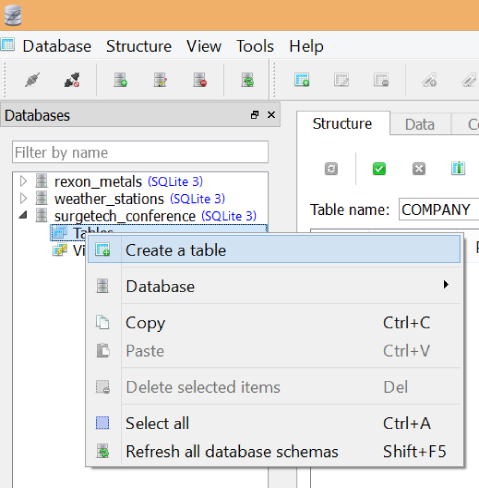
Right-click on the Tables item in the navigator and click Create a table, as shown in Figure 1-12.
Figure 1-12. Creating a table
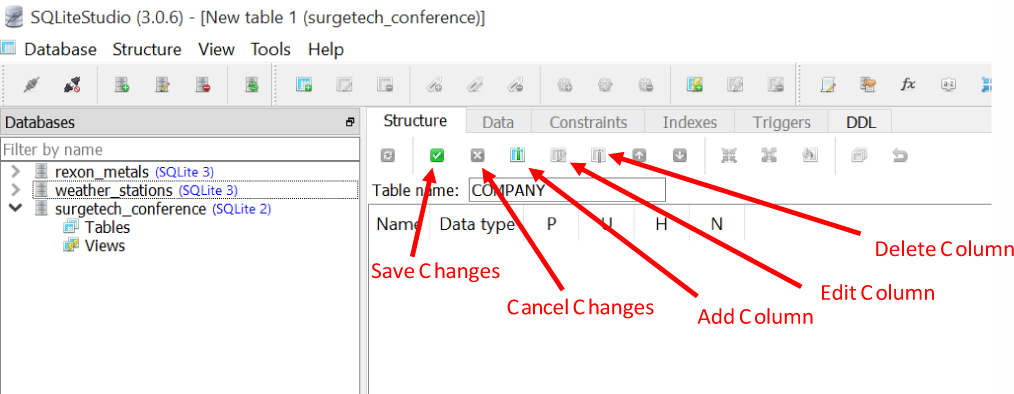
You will then come to the table Structure tab. Here we add, modify, and remove columns from our table (Figure 1-13).
Figure 1-13. The table Structure tab, which we can use to add, modify, and remove columns from a table
We can also define various constraints to ensure data entered into the columns conforms to rules we specify. We also supply a name for this table in the “Table name” field. Type in COMPANY for this table name. Also note there is a button to save your edits and another to add a new column.
Click the Add Column button, and you will see a dialog to define a new column and its attributes. Name this column COMPANY_ID and make its data type “INTEGER,” as shown in Figure 1-14.
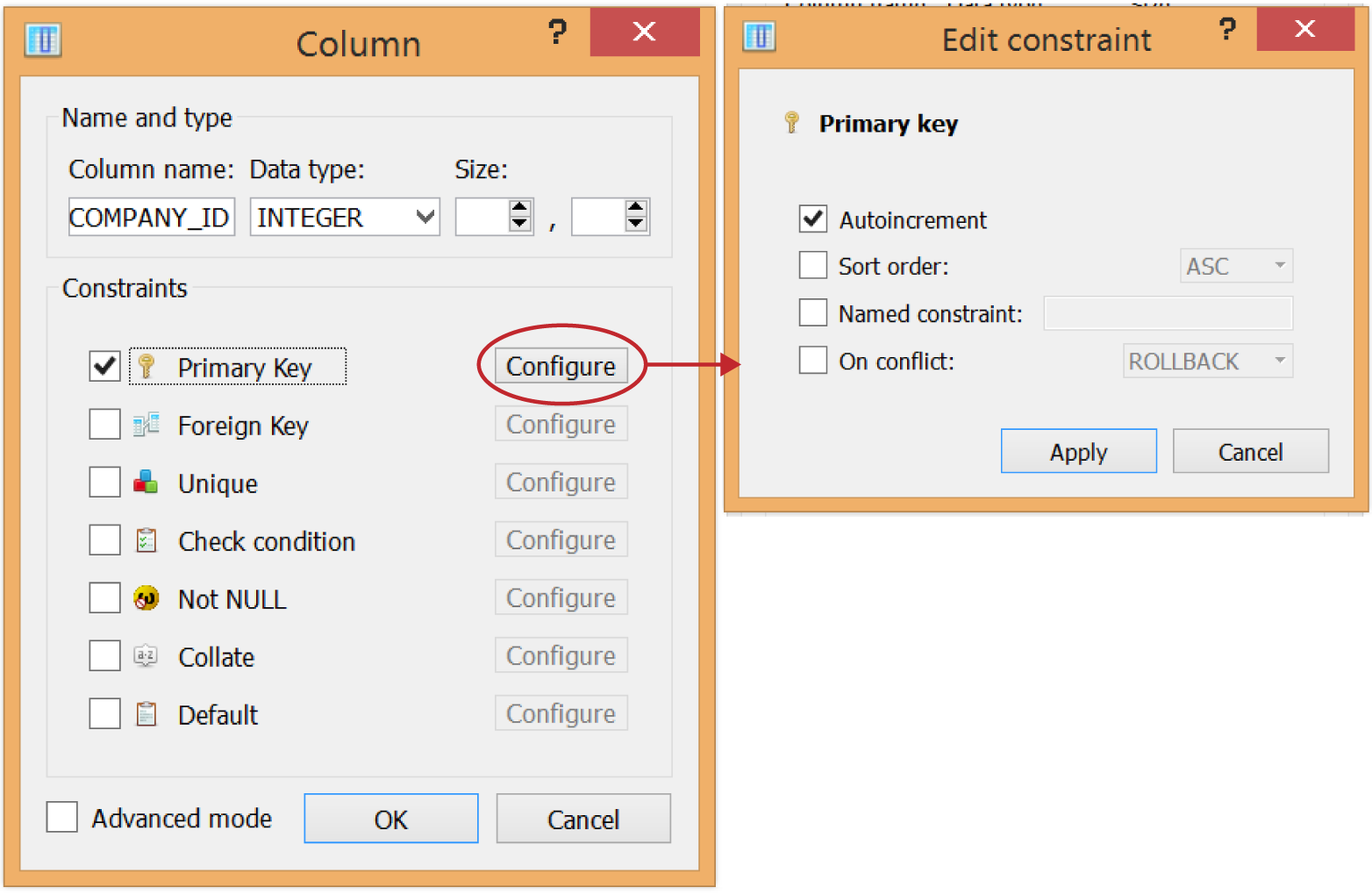
Figure 1-14. Defining a new COMPANY_ID column that holds integers; it also is configured to be the primary key and will automatically populate a value via “Autoincrement” for each inserted record
This is the COMPANY_ID field, and we need to define this as the primary key for the COMPANY table. Typically, the easiest way to assign key values is to do it sequentially for each new record. The first record will have a COMPANY_ID of 1, then the second record will have 2, then 3, and so on. When we INSERT records in the next chapter, this is a pain to do manually. But we can configure SQLite to automatically assign an ID for each record we insert. Simply check Primary Key, then click Configure, then select Autoincrement and click Apply (Figure 1-14).
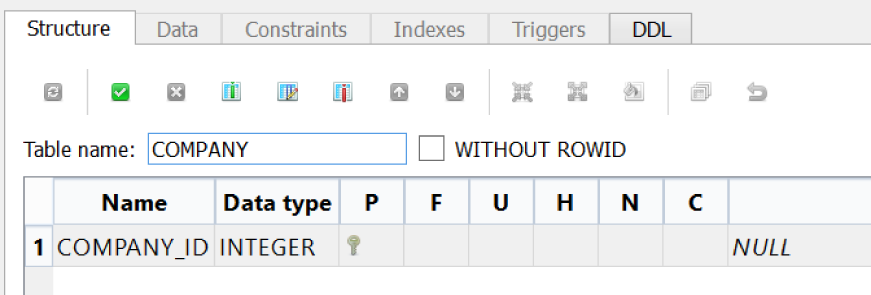
Finally, click OK in the Column window and you will see our first column defined (Figure 1-15).
Figure 1-15. Our first column is defined; notice the key symbol indicating this column is the primary key
We have now defined our first column, and because it was the primary key column, it took some extra work. The rest of the columns will be a little easier to set up.
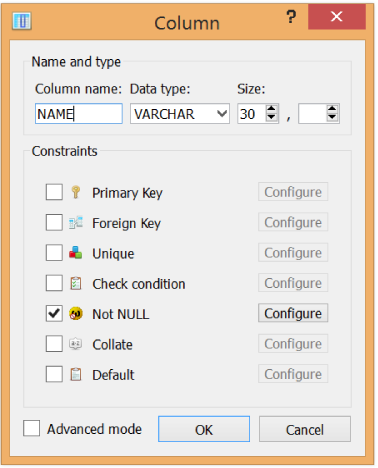
Click on the Add Column button again to create another column (Figure 1-16). Label this column NAME and make it a VARCHAR type, which is for text that can be of varying lengths. Specify the maximum number of characters to be 30. Because we likely never want this field to be null, check the “Not NULL” constraint. If any records are added or modified with NAME set to null, then the database will reject the edits.
Figure 1-16. Creating a “NAME” column with type VARCHAR, a max character length of 30, and a “Not NULL” constraint
Click OK and then create two more columns, DESCRIPTION and PRIMARY_CONTACT_ATTENDEE_ID, with the configurations shown in Figure 1-17. Note that PRIMARY_CONTACT_ATTENDEE_ID should be a foreign key, but we have not defined that yet. We will come back to configure this after we have created its parent, the ATTENDEE table.
Figure 1-17. Creating the remaining two columns
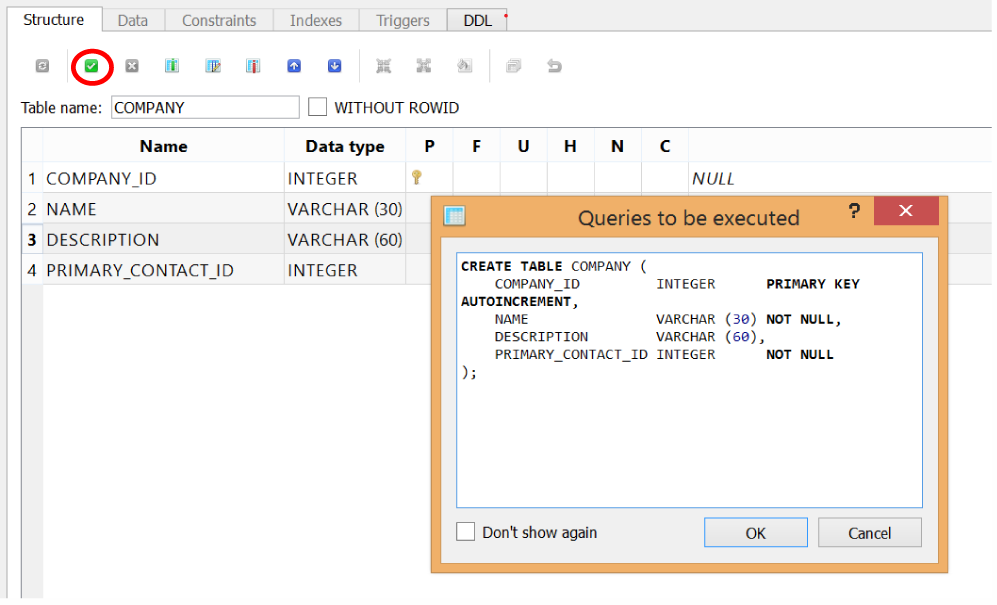
Finally, click the Save Table button. You will be presented with a CREATE TABLE statement that SQLiteStudio has built for you, and will execute on your approval (Figure 1-18).
Figure 1-18. Click the Save Table button in the top toolbar, and SQLiteStudio will present the CREATE TABLE statement it is about to execute based on our inputted definitions
How cool is that? SQLiteStudio wrote SQL for you based on all the table definitions you built. Before you click OK, let’s take a quick look at the CREATE TABLE statement to see how it works:
CREATE TABLE COMPANY (
COMPANY_ID INTEGER PRIMARY KEY AUTOINCREMENT,
NAME VARCHAR(30) NOT NULL,
DESCRIPTION VARCHAR(60),
PRIMARY_CONTACT_ID INTEGER NOT NULL
);
If you inspect the SQL query, you will see the CREATE TABLE statement declares a new table named COMPANY. After that, everything in parentheses defines the table columns. Each table column is defined by a name, followed by its type, and then any constraints or rules such as PRIMARY KEY, AUTOINCREMENT, or NOT NULL.
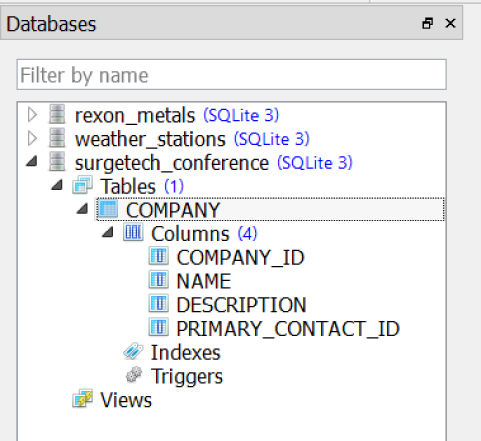
You could literally copy this statement and execute it in the SQL editor, but just click OK and it will execute the statement for you. After that, you should see your new table in the navigator (Figure 1-19).
Figure 1-19. The COMPANY table in the navigator
Note
The AUTOINCREMENT constraint in SQLite is actually not necessary. We use it here for practice because it is necessary for other platforms, including MySQL. In SQLite, making a column of type INTEGER a primary key will automatically make it handle its own ID assignment. As a matter of fact, it is actually more efficient in SQLite to not use AUTOINCREMENT and let the primary key implicitly do it.
Create the remaining four tables in the same manner. The needed CREATE TABLE statements are shown here (you can choose to build the tables using the Structure tab or just execute the CREATE TABLE statements verbatim in the SQL editor):
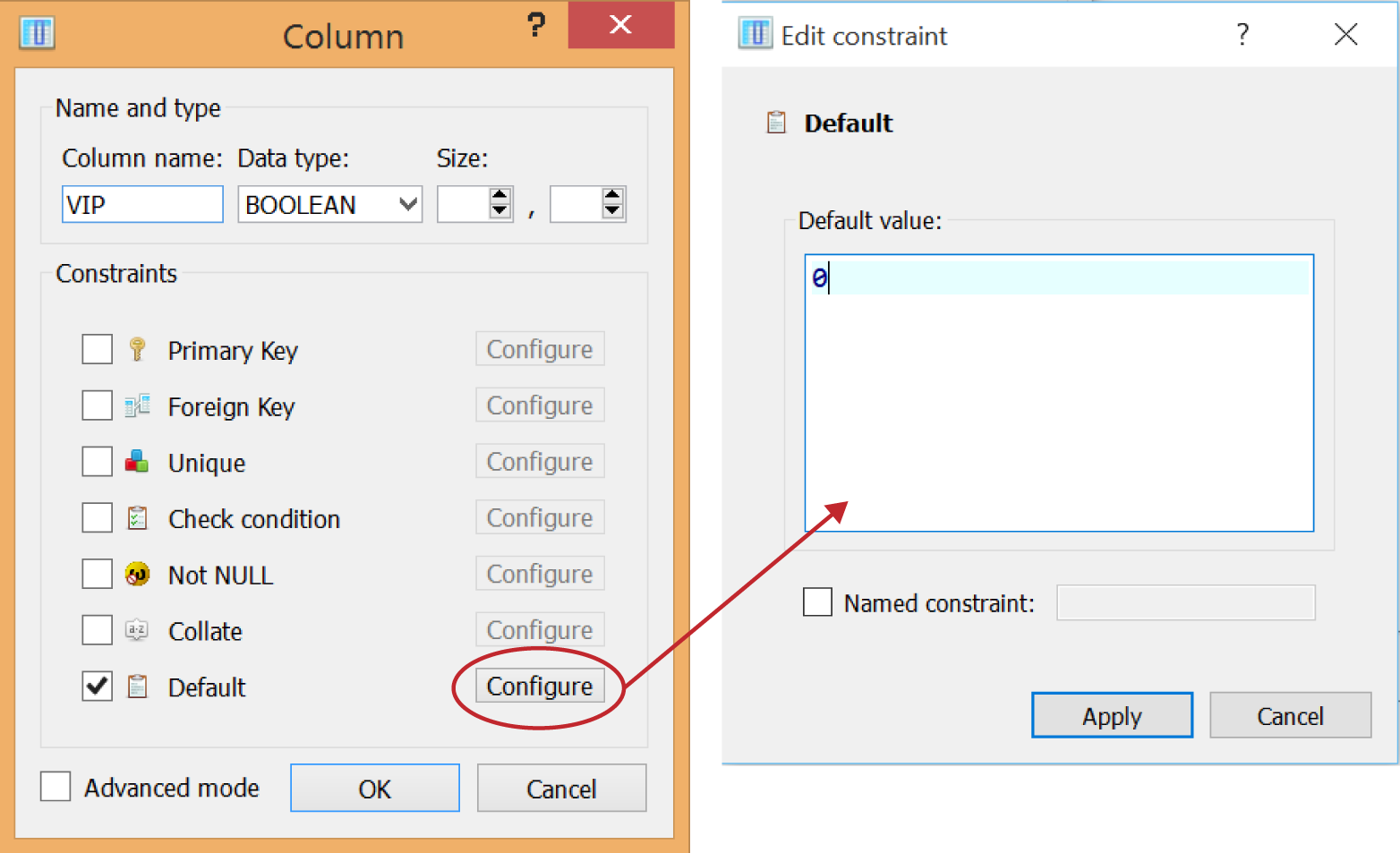
Note that the ATTENDEE table has a VIP field which is a Boolean (true/false) value. By default, if a record does not specify a value for a column, the value will default to null. It might be a good idea to default this particular field to false (0) if a value is never provided. The preceding SQL snippet reflects this, but you can also accomplish this in the column builder as shown in Figure 1-20.
Figure 1-20. Setting a default value for a column
By now, you should have all five of your tables created with all constraints defined, except the foreign keys (Figure 1-21).
Figure 1-21. All tables have been built
Note
Most database solutions enforce values in a column only by the specified data type. SQLite does not. In SQLite, you can put a TEXT value in an INTEGER column. Other database solutions will disallow this. While this seems counterintuitive, the creators of SQLite made it this way for technical reasons beyond the scope of this book.
Setting the Foreign Keys
There is one last task remaining to make our tables airtight. We have defined the primary keys but not the foreign keys. Remember that the foreign key in a child table is tied to the primary key of a parent table. Logically, we should never have a foreign key value that does not have a corresponding primary key value.
For example, we should never have a PRESENTATION record with a BOOKED_COMPANY_ID value that does not exist in the COMPANY table’s COMPANY_ID column. If there is a BOOKED_COMPANY_ID value of 5, there had better be a record in COMPANY with a COMPANY_ID of 5 as well. Otherwise, it is an orphaned record. We can enforce this by setting up foreign key constraints.
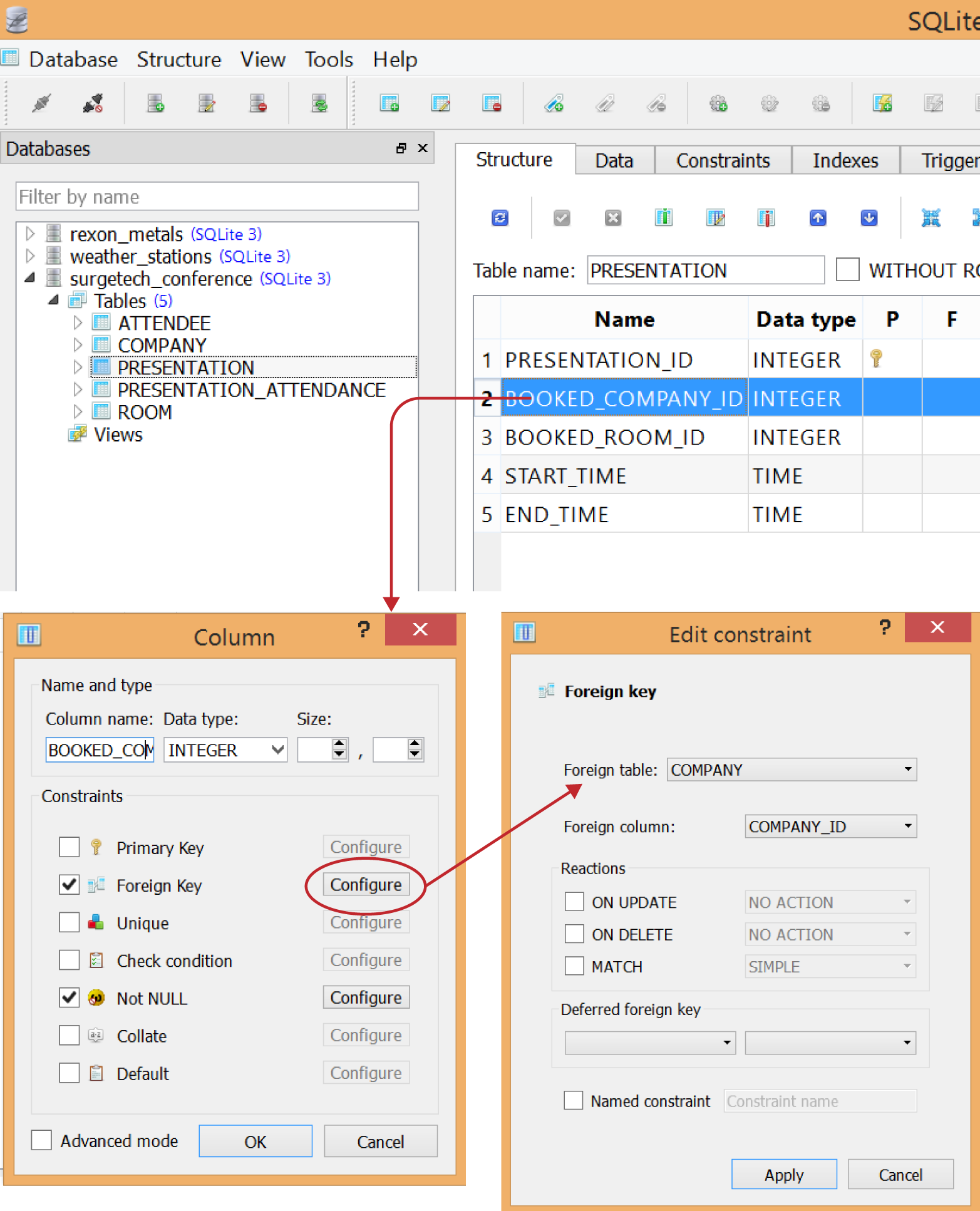
Open up the PRESENTATION table and double-click the BOOKED_COMPANY_ID column to modify it (Figure 1-22). Check Foreign Key and then click Configure. Set the foreign table to CUSTOMER and the foreign column to CUSTOMER_ID. This will constrain BOOKED_COMPANY_ID to only the values in the CUSTOMER_ID column in the CUSTOMER table. Click Apply, then OK.
Figure 1-22. Making BOOKED_COMPANY_ID a foreign key to COMPANY_ID in the COMPANY table
Click the Commit Changes button on the Structure tab, and a series of SQL statements will be generated to implement the foreign key. You can look at the SQL if you are curious, but it will only make you appreciate all the work that SQLiteStudio has done for you. Then click OK to commit the change.
Using foreign keys keeps data tight and prevents deviant data from undermining the relationships. We should define foreign key constraints for all relationships in this database so no orphan records ever occur.
At this point, you can create foreign keys for all of the following parent–child relationships by repeating the same procedure:
Create foreign key for [Table].[Field]
Off parent primary key [Table].[Field]
PRESENTATION.BOOKED_ROOM_ID
ROOM.ROOM_ID
PRESENTATION_ATTENDANCE.PRESENTATION_ID
PRESENTATION.PRESENTATION_ID
PRESENTATION_ATTENDANCE.ATTENDEE_ID
ATTENDEE.ATTENDEE_ID
COMPANY.PRIMARY_CONTACT_ATTENDEE_ID
ATTENDEE.ATTENDEE_ID
Now we have ensured every child record has a parent record, and no orphans will ever be allowed into the database.
Note
If you ever use SQLite outside SQLiteStudio, note that the foreign key constraint enforcement might have to be turned on first. SQLiteStudio has it enabled by default, but other SQLite environments may not.
Creating Views
It is not uncommon to store frequently used SELECT queries in a database. When you save a query in a database, it is called a view. A view behaves much like a table. You can run SELECT statements against it and join it to other views and tables. But the data is completely derived from a SELECT query you specify, so in many cases you cannot modify the data (nor would it make sense to).
Suppose we run a SELECT query very often to give us a more descriptive view of the PRESENTATION table, which pulls in the booked company and booked room information:
SELECT
COMPANY.NAME as BOOKED_COMPANY,
ROOM.ROOM_ID as ROOM_NUMBER,
ROOM.FLOOR_NUMBER as FLOOR,
ROOM.SEAT_CAPACITY as SEATS,
START_TIME,
END_TIME
FROM PRESENTATION
INNER JOIN COMPANY
ON PRESENTATION.BOOKED_COMPANY_ID = COMPANY.COMPANY_ID
INNER JOIN ROOM
ON PRESENTATION.BOOKED_ROOM_ID = ROOM.ROOM_ID
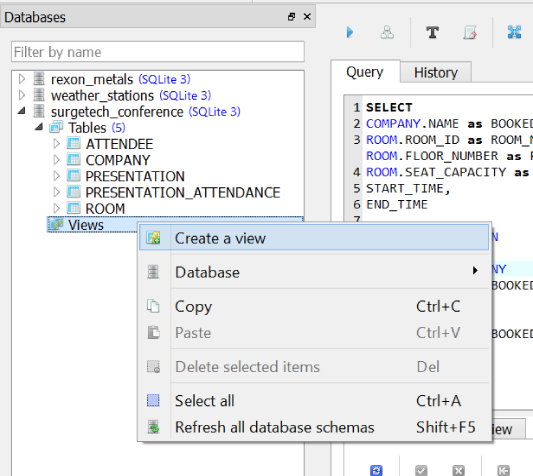
Now suppose we want to store this query in the database so it can easily be called. We can do that by right-clicking the Views item in the navigator, then clicking Create a view (Figure 1-23).
Figure 1-23. Creating a view
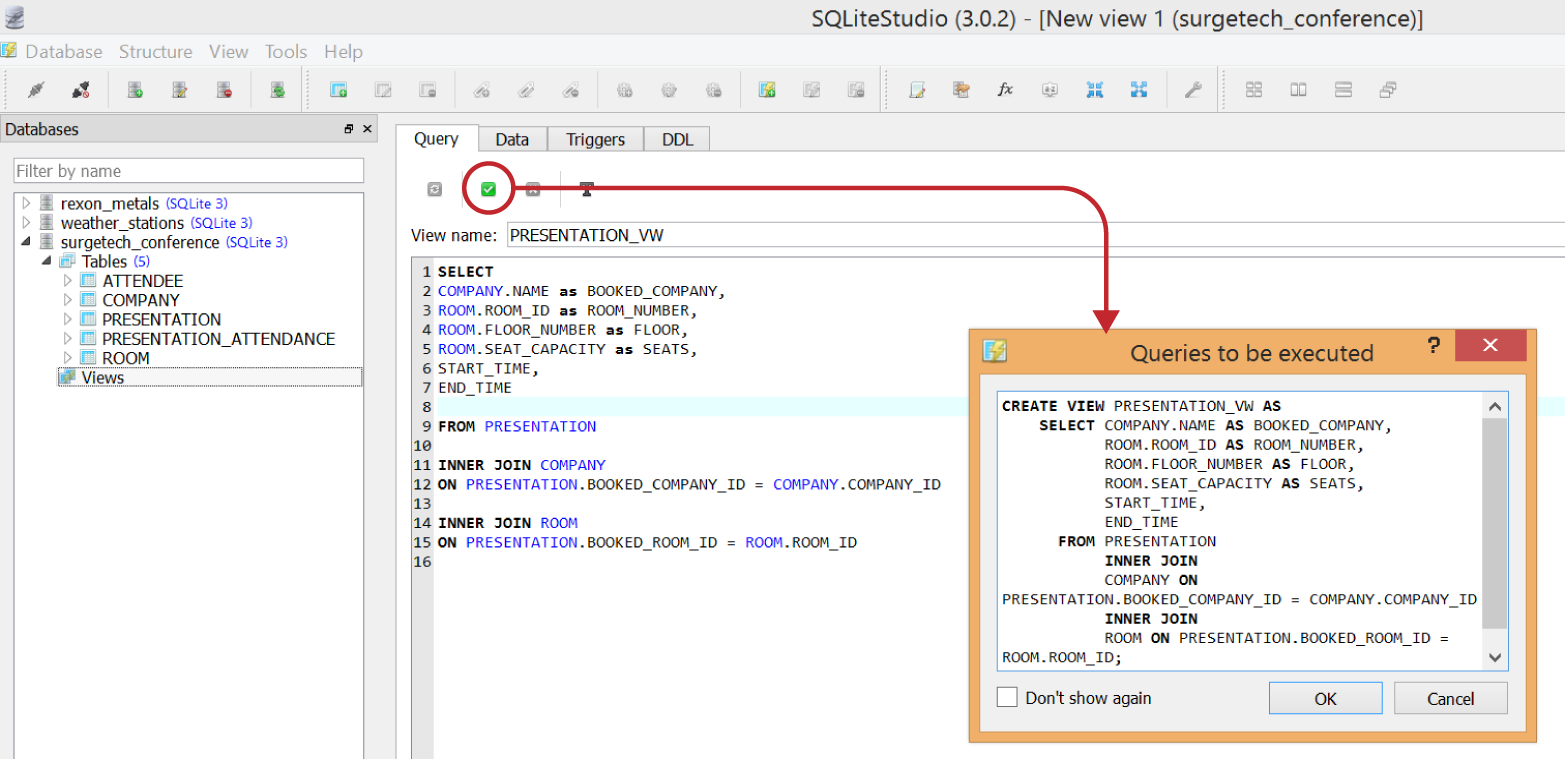
You will then be taken to a view designer window (Figure 1-24). Navigate to the Query tab. Here you will paste your SELECT statement. In the “View name” field, name this view PRESENTATION_VW (with “VW” an abbreviation for “VIEW”), and click the green checkmark to save it. Before it executes the SQL query to create the view, SQLiteStudio will present it for review. As you can observe, the SQL syntax to create a view is fairly simple. It is CREATE VIEW [view_name] AS [a SELECT query].
Figure 1-24. Creating a view off a SELECT query
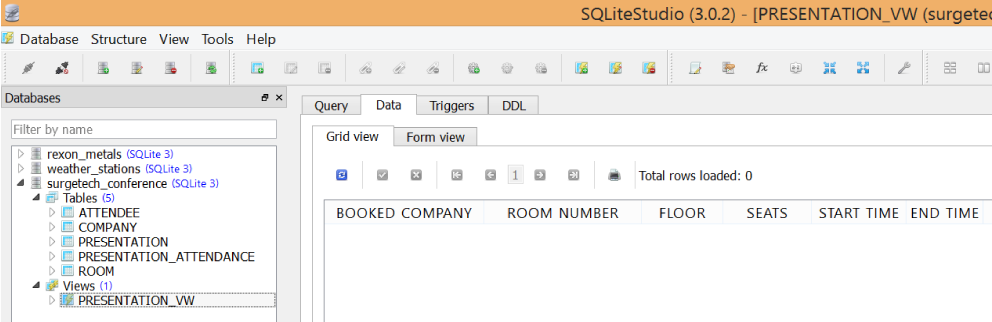
When you click OK, you should now see the view in your navigator under “Views” (Figure 1-25). Double-click on it and in the Query tab you will see the query it is using, and the Data tab will have the query results.
Figure 1-25. Although there is no data yet, the SELECT query has been saved as a view called PRESENTATION_VW
The Data tab will be blank, until the queried tables are populated with data.
Note also that we can query from a view just like it was a table (and apply filters, do join operations, and do anything else you could do in a SELECT with a table):
SELECT * FROM PRESENTATION_VW
WHERE SEAT_CAPACITY >= 30
Summary
In this chapter, we dived into creating our own databases and learned how to design them efficiently. We studied table relationships, which help us clearly define how tables are joined. We also explored some of the various column constraints (including PRIMARY KEY, FOREIGN KEY, NOT NULL, AUTOINCREMENT, and DEFAULT) to keep data consistent and ensure it follows rules we define.
In the next chapter, we will actually populate and modify data in this database. We will witness our design at work and appreciate the time we put into planning it. A good design with well-defined constraints will make a resilient database.
Note
One topic this chapter did not cover is indexes. Indexes are useful for tables with a large number of records but have performance issues with SELECT statements. not available discusses indexes and when and when not to use them.