Enhancing persistence with open source infrastructure
Having a homogenous approach to persistence is key to moving the container ecosystem forward.
 Container (source: Pixabay)
Container (source: Pixabay)
In the past, we installed applications on hosts. Now we deploy ephemeral containers from container images and don’t worry about the host, which is great for promoting efficiency and scale. But if the application in the container is a database and it needs to maintain its state, problems can arise. When you have to worry about the availability of the data, you’ve reintroduced the host into the process, and undercut the advantages you gain from using containers. If we agree that adopting containers across the industry is a useful goal, containers are going to need some sort of persistence and awareness of storage platforms. Having a homogenous approach to persistence across the container ecosystem is key to moving forward in sustainable ways. The EMC {code} team is delivering this through two open source projects. Learn more about project REX-Ray, a storage storage orchestration project, and Polly, a storage scheduling project.
Container runtimes
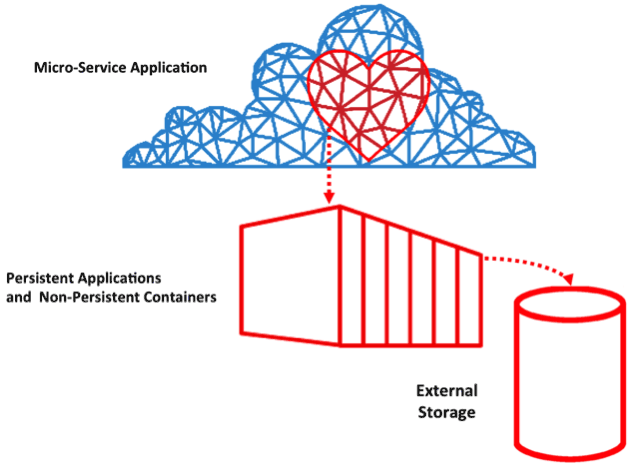
Today, persistence is brought to many platforms through internal components. The components form a dependent stack to create a container platform starting with the lowest layer being the container runtime. On top of this is the container scheduler, followed by the application scheduler or framework. The goal is to get to a state where the data for applications is handled abstractly and separated from the container host, yet integrated into the application. The following picture describes a microservices application with critical storage resources being managed as part of the application, but with persistence being made available through containers attached to a storage platform.

Learn faster. Dig deeper. See farther.
The container runtime is where the heavy lifting occurs for creating and removing containers. When a request comes in, the container runtime does the important orchestration work of connecting containers to the storage platform to retrieve the desired resources. Putting together a container that can handle those requests properly gives you composability, so all layers in the container stack can request the data with the container in a consistent manner. Exactly how the storage platforms integrate with the container runtime tends to differ depending on the runtimes you’re using. The runtime might have internal knowledge of a specific storage platform, or the runtime might connect through well-defined APIs. The API approach is more sustainable because it decouples the storage platform from the container runtime, meaning that the storage solution can be swapped out for another one using the same API, with no affect on the rest of the container components. Additionally, new storage platform options can arise simply by adhering to the public API.
Schedulers
Above the container runtimes, you’ll find the schedulers, which also need to know about the storage platform. These schedulers manage the availability and placement of containers for the applications. As they schedule the containers, they expose the runtime features of the lower layers, including storage.
To enable persistent applications to run in containers, the storage solution needs to provide features for both the container runtime and scheduler. This allows storage volumes to outlive the containers that host the applications and ensures they’re released when not in use. The container host should never maintain any unique data. Such a system makes high availability possible for persistent applications and containers across various container hosts.
Application frameworks
You also need to ensure that the lifecycle of storage volumes is handled separate, yet automatically with your containers. To do this, you need container platform administrators or even application frameworks to autonomously create storage volumes, and to claim available storage directly. For instance, if an application needs more performance or capacity it should be able to request this capacity and scale-out when needed. These components in turn depend on the container schedulers mentioned earlier. Application frameworks help to keep an application healthy as it responds to changes in load or availability. If these frameworks are aware of persistent storage, you can expand the functionality and availability of the application controlled by the framework.
The container runtime and schedulers make up a critical part of open source infrastructure. Getting these layers working together with persistence will ensure all applications fully benefit from containers. The EMC {code} team delivers persistence to containers in sustainable ways through two focused projects. Project Polly is a single storage scheduling service that can simultaneously talk with container and application schedulers of different types, delivering offers in the form of storage resources. Project REX-Ray then handles the work of plumbing heterogeneous storage, including scheduling to containers, if necessary.
The EMC {code} community is a great place to join these conversations. Help us move the discussion forward and further enhance persistence with open source infrastructure. Come to our sessions at OSCON on Wednesday and Thursday, May 17-18, to hear more about where the container ecosystem is with persistence today and where things are going.
This post is part of a collaboration between O’Reilly and EMC. See our statement of editorial independence.