Best kept machine learning secret in security
Ranking algorithms bolster intrusion detection systems.
 "Les femmes et le secret," by Tony Johannot (source: Via oldbookillustrations.com)
"Les femmes et le secret," by Tony Johannot (source: Via oldbookillustrations.com)
The allure of using machine learning in data security comes from its ability to generalize attack detection based on historical data and to detect attacks that would not be obvious otherwise. Machine learning in security analytics is gaining widespread adoption, and the security analytics market is projected to hit $7.1 billion by 2020.
The biggest challenge in using machine learning for data security has to do with triaging, or prioritizing, alerts effectively. In my last post, I explored how to prevent false alerts in data security. Here, we’ll explore how a generalizable algorithm-based system can detect security breaches, using ranking algorithms from the information retrieval domain. These algorithms can help security data scientists triage the alerts they do receive.

Learn faster. Dig deeper. See farther.
As an example, let’s consider the infamous Target breach, where investigations revealed that the company’s intrusion detection system raised multiple alerts that were directly tied to the attacker’s activity—but they were all overlooked by security analysts. This is not because the analysts were incompetent, but rather because they were overwhelmed by a deluge of alerts (cognitive overload leading to oversight). In order to successfully detect an attacker within the system, we need to stop using independent alert streams and lessen the security analyst’s burden of triage.
Issues with current security detection systems
There are two notable issues with current security detection systems:
-
Independent alert streams (N*k problem): Among today’s systems, each detection typically has its own alert stream. There are detections for spotting unusual processes, for anomalous logons, and credential elevation, to name a few. Each detection, whether it’s signature-based or behavorial-based, independently spews forth a laundry list of “top” anomalous alerts.
I call this the N*k problem—if you have N detections, and each detection puts forth a list of top k alerts, you have N*k alerts. So, if you had seven detections, each sending a top-10 list of anomalous alerts, an analyst has to triage 70 different security alerts! Unless there is a plethora of analysts, it becomes incredibly difficult to triage all of the alerts in a reasonable amount of time.
- Burden of triage on analysts: A related problem is that the burden of triage is placed on the human in the loop. In practice, there are certain kinds of alerts that need more immediate attention, while others can be downgraded. An analyst is making a judgment every time she acts on an alert, but this feedback is not always effectively captured. Ideally, the system should automatically triage alerts—assigning them in order of urgency—and present the results in a rank-ordered list. At the top of the list should be the highest priority alerts, which need to be immediately investigated and addressed, so that the analyst can focus on the alerts that are most critical to the business.
Ranking algorithms
One way to effectively tackle both of these problems is to use ranking algorithms. At its core, ranking is an information retrieval problem—you ask the system a question, the system looks through the corpus, and it retrieves what it determines are the best answer(s) to your question. By varying how we ask the question, we have an impact on what kind of answers and applications we receive. For example, a Web search asks the system to retrieve the most relevant Web pages to a search query, recommender systems might ask to retrieve the most relevant movies based on a user’s activity, and more arcane domains like prioritizing emails can rank emails based on previous usage.
One thing to note is that ranking algorithms are a supervised problem—you need to bootstrap the system by showing it how the ranking should look. However, unlike run-of-the-mill supervised algorithms, ranking systems in practice need way fewer labels—even a ratio of 10 labels in a pool of one million will yield good results.
Ranking to improve the analyst-to-machine feedback loop
Ranking algorithms are a natural fit for addressing the issue of alert triage. They can be used to capture an analyst’s feedback and incorporate that feedback into the system. Every time an analyst makes a determination about a security alert, marking it as either a false positive or a true positive, the system “learns” from that feedback, improving future results.
This feedback loop ensures two things:
- The system is tailored to an analyst, or group of analysts, which means in the future, only those alerts that the analysts are more likely to find useful and relevant are surfaced. As a corollary, the system also learns to push the most relevant alerts up in priority, pushing down those that are less useful.
- As a result, there is no longer an ambiguous laundry list of alerts that analysts must triage—the end product is a definite, stack-rank ordered list of alerts that has been auto-triaged by the system.
Ranking to combine independent alert streams
Ranking also solves the N*k problem. One of the subtleties of using ranking is that it provides a set of weights to determine the rank order of each detection. By having multiple detections evaluating the same session and training a ranking system that is tailored to the analysts, we can get the relative weight of each detection. Thus, every detection [d1.….dn] would output normalized probabilities, converted to probabilities [p1…..pn], and would have weights [w1..…wn], which are then combined using Totalscorei= wTpi (where pi is the set of probabilities of the ith session, and w is the weight vector determined by ranking algorithm). The ranked weights provide a nice interpretation of the relative importance of all detections.
For instance, consider we have four detections in our system:
a) Unusual Process Creation
b) Unusual Time of Access
c) Credential Leak
d) Data Exfiltration
Given an alert, how do we know which of the detections is most responsible for the alert? To answer this question, we can dig into the weights. Because ranking algorithms provide us weights for each of the detections, we can use them to understand the root cause for each alert. The following is an illustration, with hypothetical weights attached to each detection.
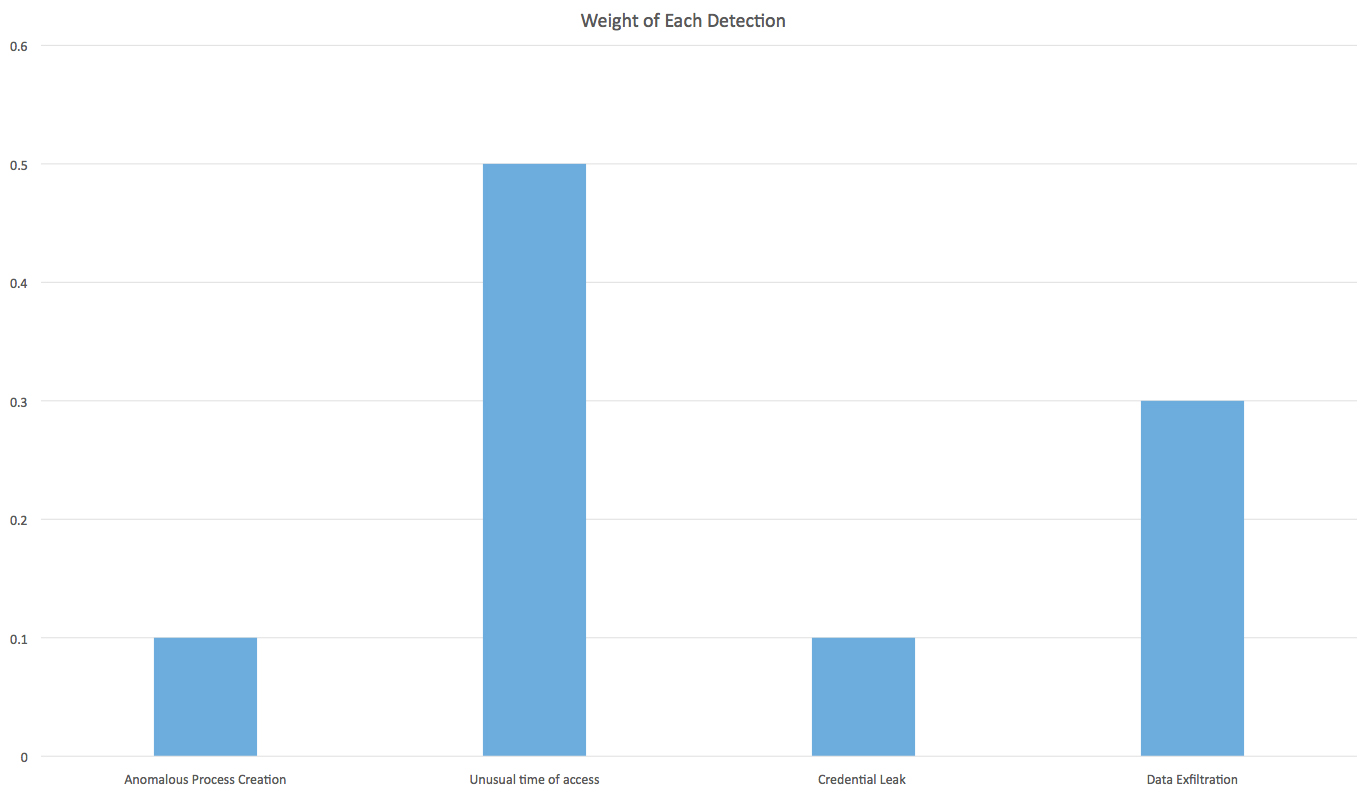
In this figure, we can see that the unusual time of access has the highest weight, which means it is most likely the reason for triggering the alarm. Now, we have a way to de-multiplex the stream of detection to identify a root cause.
There is also another use—if we find that one of the detections is constantly being down-weighted, we should consider whether the underlying detection is still relevant. For example, perhaps the environment has changed in such a way that the detection is no longer relevant. This interpretation will help us to cull outmoded detections—saving us storage and compute space, and most importantly, analyst time and effort.
If you are looking to try ranking algorithms, I recommend starting with a linear ranker, like RankNet (this is the same algorithm that was the precursor to Microsoft’s Search engine)—its results are easy to interpret and understand. Online packages for ranking can be found on RankLib.