Apache Mesos: Open source datacenter computing
Mesos offers reliability, efficiency, and faster developer productivity.
Virtual machines (VMs) have enjoyed a long history, from IBM’s CP–40 in the late 1960s on through the rise of VMware in the late 1990s. Widespread VM use nearly became synonymous with “cloud computing” by the late 2000s: public clouds, private clouds, hybrid clouds, etc. One firm, however, bucked the trend: Google.
Google’s datacenter computing leverages isolation in lieu of VMs. Public disclosure is limited, but the Omega paper from EuroSys 2013 provides a good overview. See also two YouTube videos: John Wilkes in 2011 GAFS Omega and Jeff Dean in Taming Latency Variability… For the business case, see an earlier Data blog post, that discusses how multi-tenancy and efficient utilization translates into improved ROI.

Learn faster. Dig deeper. See farther.
One takeaway is Google’s analysis of cluster traces from large Internet firms: while ~80% of the jobs are batch, ~80% of the resources get used for services. Another takeaway is Google’s categorization of cluster scheduling technology: monolithic versus two-level versus shared state. The first category characterizes Borg, which Google has used for several years. The third characterizes their R&D goals, a newer system called Omega.
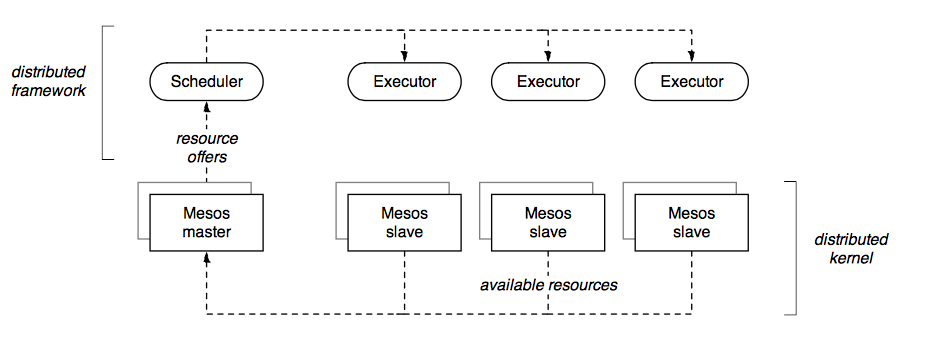
Meanwhile, the second category – a two-level scheduler – characterizes an open source project called Apache Mesos. It began as grad student research at UC Berkeley EECS and last summer became a top-level Apache project. Ben Hindman, principal author of Mesos, moved from Berkeley to Twitter two years ago, bringing expertise that helped deprecate the “Fail Whale” and helped position the company to scale-out services on its ramp towards IPO.
Twitter’s engineering blog describes Mesos as “the cornerstone of our elastic compute infrastructure.” In other words, Mesos provides Amazon AWS-like elasticity for Twitter’s bare metal clusters, described at meet-ups as ranging up to 150,000 cores in size. This obviates the need for VMs – following Google’s datacenter strategy. Chris Fry, SVP Engineering described Mesos in a recent Wired interview:
We can get reliability and efficiency at the same time on top of faster developer productivity as well.
The technology relies on Linux cgroups for isolation, while introducing a new abstraction layer. Layering atop a distributed file system – HDFS by default – Mesos acts as a distributed kernel, accessed via APIs in C++, JVM, Python, and Go. The new abstraction layer introduces a scheduler, to receive resource offers from the Mesos master, and an executor, to consume scheduled resources and thus perform tasks or run services on the Mesos slaves. In Mesos terminology, the scheduler/executor layer is called a framework. Applications then run atop frameworks.
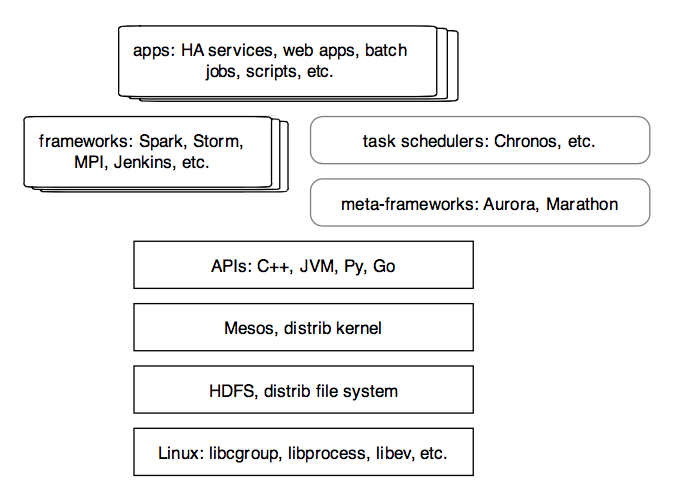
Apache Spark, Apache Hadoop, Storm, MPI, Hypertable, DPark, and Jenkins are example frameworks which can take advantage of Mesos. Additionally, meta-frameworks such as Aurora from Twitter and Marathon from Mesosphere, launch frameworks – or any long-running process that runs on Linux – leveraging Mesos to provide high-availability for those processes. Task schedulers, e.g., Chronos from Airbnb, get launched from meta-frameworks and schedule batch jobs. Those may range from Bash scripts to Hadoop jobs.
Consider an analogy… after a Linux kernel boots, the first process is init.d, which launches cron as the initial service. Taking the analogy of Mesos as a distributed kernel, then Aurora and Marathon provide a distributed init.d, while Chronos provides a distributed cron.
The resources being offered and isolated include: CPU upper/lower bounds, RAM allocation, I/O network controller, plus some aspects of the file system. The latter is complex, but more FS isolation features are in progress. Also, cgroups allow “ad-hoc” resource descriptions to be added on the fly. Those could be a rack ID, to force rack locality, or a metadata repository required as a neighbor for a particular service.
The business case for Mesos is to promote an open source version of Google’s datacenter computing strategy. Tangible benefits – even for start-ups with 20+ servers – include:
- increased utilization
- reduced latency
- reduced equipment cap-ex
- reduced Ops overhead
- reduced licensing (VMs)
Latency benefits especially make sense, considering the performance cost of VMs – particularly for services on clusters with high load. Recall Google’s insight: cluster resources get thrown at services to meet SLAs. Public use cases from Twitter, Airbnb, MediaCrossing, HubSpot, Sharethrough, etc., confirm that HA services and reduced costs are the most compelling arguments for Mesos, more so than batch processing.
More subtle points from the use cases are arguably more important for Enterprise IT:
- reduced time for engineers to ramp up new services at scale
- combined production and dev/test apps on the same cluster
- reduced latency between batch and end-use services, enabling new high-ROI use cases